
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 로컬 세팅
- 파이썬 크롤링
- 자바 툴 추천
- 쿵쿵나리
- 아비투스서평
- 자바
- 웹투비 설정
- 웰씽킹 서평
- 도리스 메르틴
- 제우스 웹투비 세팅
- 웹투비제우스 연동
- Mac vue js 설치
- Java
- 웹투비 제우스7
- 아비투스후기
- 맥북 사파리 개발자도구
- JDK11 설치
- Python
- 파이썬
- 서평
- Jeus Webtob
- Vue js v-bind:key
- 이선미
- webtob 설치
- VUE js 에러
- json
- JAVA JDK 다운로드
- 맥북 vue.js 설치
- 맥북 개발자도구 단축키
- Mac 개발자도구
- Today
- Total
개발일기 정답찾기
OLTP OLAP 차이 - Parquet, AWS에 사용에 앞서서.. - 유딩동 Tistory 본문
유딩동입니다. 프로젝트에서 AWS를 사용하고 있습니다.
매달 꽤나 많은 데이터를 처리해서인지 한달에 50만원 정도의 과금이 진행되고 있습니다.
현재 우리는 많은 데이터를 가지고 있고, 온프레미스(On-premise)에선 오라클로 row base DB를 사용합니다.
AWS에서는 현재 column base DB를 사용하기 까지, 조금 정리해 보았습니다.
Row Based VS Column Based

Row Based : Oracle, PostGreSQL / 장:CRUD 쉬움 / 단:불필요한 데이터까지 모두 봐야함
Column Based : Redshift(Amazon), Cassandra, Hbase(Apache) / 장:필요한 데이터만 빠르게 볼 수 있음 / 단:입력 불편
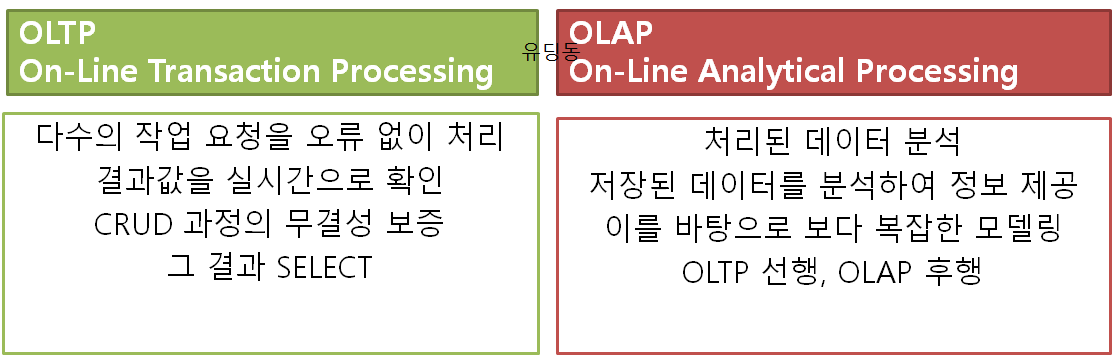
OLTP VS OLAP
Parquet 파켓 데이터 정의
Apache Parquet는 Apache Hadoop 에코 시스템의 무료 오픈 소스 열 지향 데이터 스토리지 형식입니다.
하둡에서 사용할 수있는 다른 컬럼 스토리지 파일 형식 인 RCFile 및 ORC와 유사합니다.
Hadoop 환경에서 대부분의 데이터 처리 프레임 워크와 호환됩니다.

파켓 형태를 처음 마주치게 된 것은 데이터레이크(datalake) 프로젝트 중, 방대한 데이터를 수집하긴 했는데, 그 이후에 분석 처리를 어찌 해야할 것인가 였습니다.
빠르게 읽고, 비용을 적게 - 즉 높은 압축률, 낮은I/O
트위터에서 개발하고 아파치에서 현재 관리중입니다.

실제로 우리 프로젝트에서 parquet 형태로 저장되어있는 파일들이 정말 많은데,
AWS 내부에선 사용하고 있지만 직접 파일을 열어본 적은 없습니다.
데이터레이크에서는 parquet 형태로 수억, 수십억의 데이터를 읽어오는 데 시간을 얼마나 줄일 수 있을지 다양한 시도중입니다.

형태가 다음과 같다고 합니다. 저도 참고정도만 하려고 이미지를 붙여왔습니다.
다음은 Amazon S3의 스토리지 요금 입니다.

CSV가 Row Base인데,
Parquet(Column Base) 형태는 CSV보다 디스크 공간을 훨씬 적게 차지 하는 것을 알 수 있습니다.
데이터를 읽어오는 속도가 빠르고, 훨씬 저렴합니다.

비용면에서 보신다면 훨씬 더 와닿으실 겁니다.
일반 CSV파일이 20달러 였던 것이, 1.25달러로 무려 16배나 줄어들었습니다.
그렇기에 우리는 OLTP가 아닌 OLAP로 빅데이터를 활용하기 위하여 Parquet 형태를 선택하였습니다.
앞으로 AWS Glue를 이용하여 Parquet형태로 변환해 나가는 과정을 포스팅 하겠습니다.
참고
https://www.slideshare.net/larsgeorge/parquet-data-io-philadelphia-2013
https://towardsdatascience.com/csv-files-for-storage-no-thanks-theres-a-better-option-72c78a414d1d
'IT > cloud' 카테고리의 다른 글
| Apache Spark 분산 처리 시스템 - 유딩동 Tistory (0) | 2021.12.06 |
|---|---|
| AWS Glue 개념정리, Crawler - 유딩동 Tistory (0) | 2021.11.17 |
