
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬 크롤링
- Mac vue js 설치
- webtob 설치
- VUE js 에러
- 이선미
- Mac 개발자도구
- 자바 툴 추천
- JAVA JDK 다운로드
- 파이썬
- Vue js v-bind:key
- JDK11 설치
- 웰씽킹 서평
- 쿵쿵나리
- Python
- 도리스 메르틴
- 웹투비 제우스7
- json
- 웹투비제우스 연동
- 자바
- 서평
- 아비투스서평
- 웹투비 설정
- 아비투스후기
- 맥북 vue.js 설치
- 로컬 세팅
- 맥북 개발자도구 단축키
- Java
- 맥북 사파리 개발자도구
- 제우스 웹투비 세팅
- Jeus Webtob
- Today
- Total
개발일기 정답찾기
[파이썬] 크롤링 Selenium 예제, 웹크롤러 만들기 - 유딩동 Tistory 본문
안녕하세요, 유딩동입니다.
BeautifulSoup만 사용하는 것이 한정적이기 때문에
Selenium 예제를 가지고 와 봤어요~!
↓ 파이썬 BeautifulSoup 사용예제 ↓
[파이썬] 크롤링 BeautifulSoup 사용법, 웹크롤러 만들기 - 유딩동 Tistory
안녕하세요, 유딩동입니다. 웹크롤러를 만들기 위해서 하나씩 차근차근 정리해보려고 합니다. https://11uding.tistory.com/9 [파이썬] 크롤링 requests 패키지 임포트 - 유딩동 Tistory 안녕하세요, 유딩동입
11uding.tistory.com
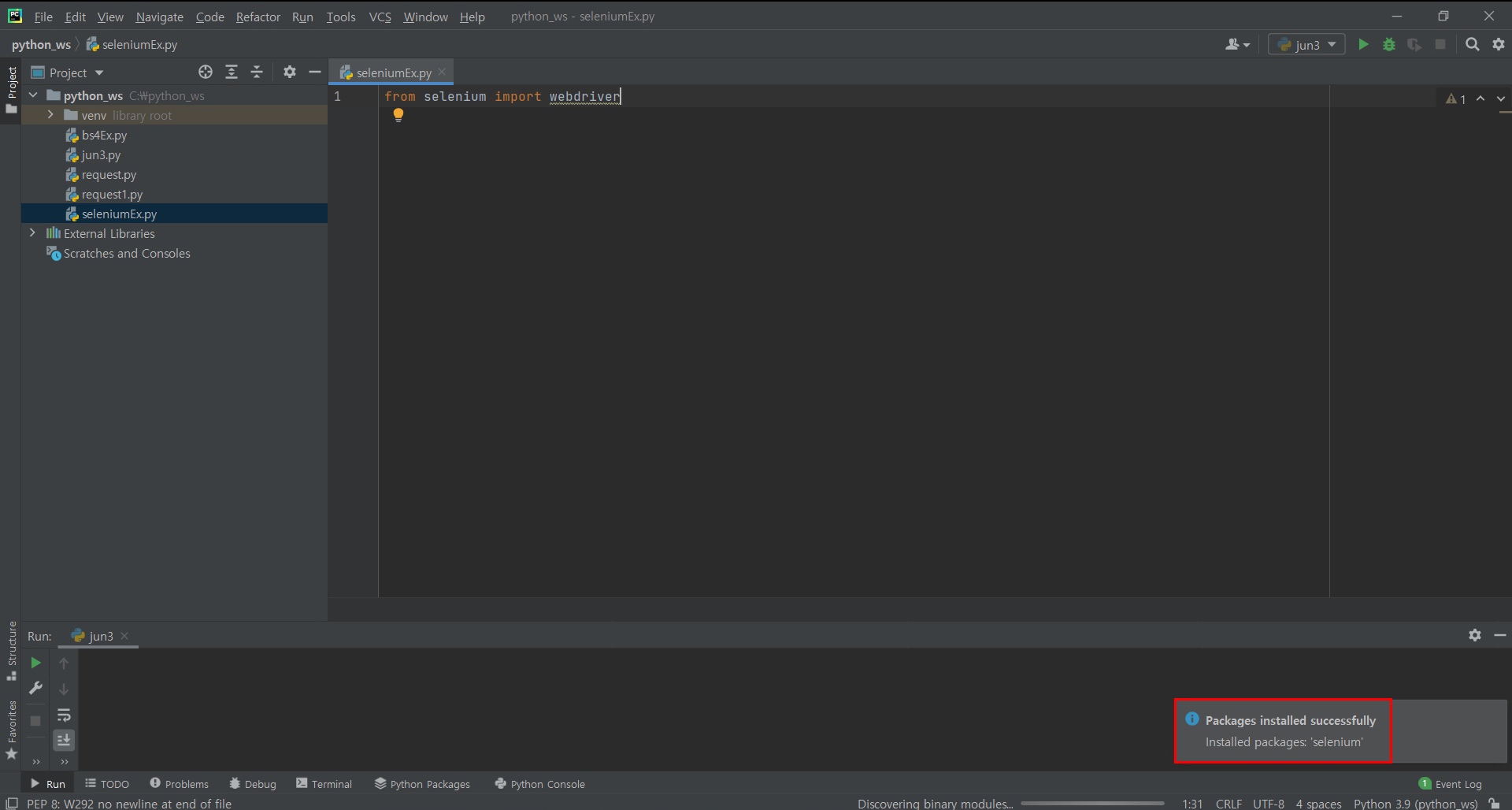
1. 패키지 insntall 해줍니다.

2. 패키지 설치 완료! XD
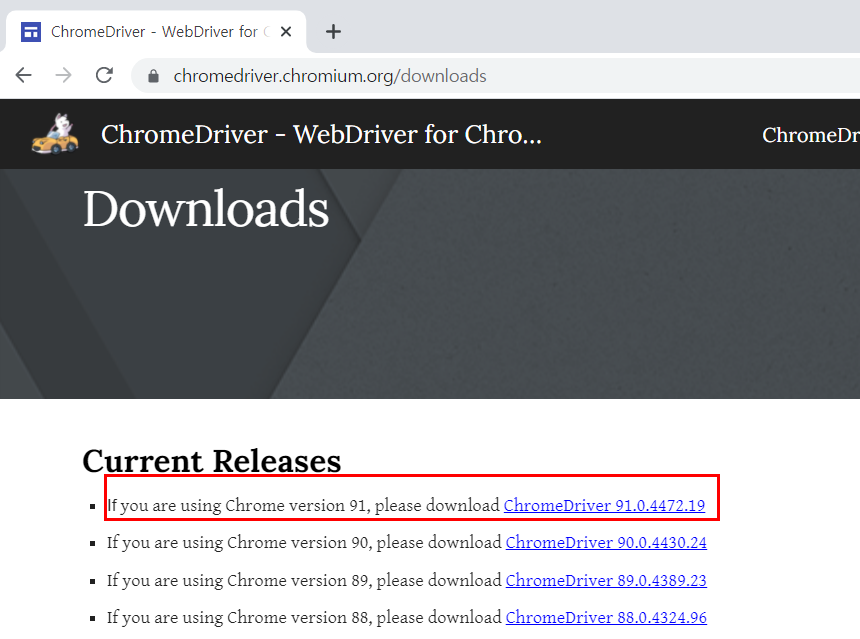
3. chromedriver 다운 해줍니다.
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 91, please download ChromeDriver 91.0.4472.19 If you are using Chrome version 90, please download ChromeDriver 90.0.4430.24 If you are using Chrome version 89, please download ChromeDriver 89.0.4389.23 If yo
chromedriver.chromium.org
여기서 다운하시기 전에, 버전을 아무거나 설치하시면 안돼요!
크롬탭을 열고, chrome://version 버전을 확인하시고 맞게 다운 해주셔야 합니다.

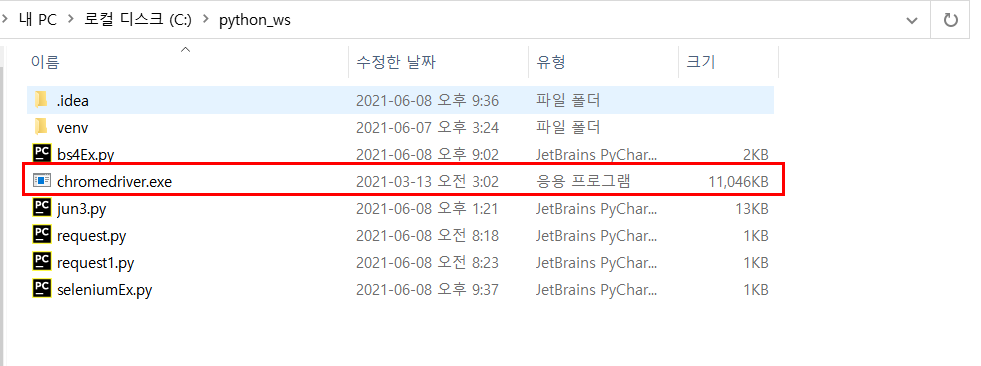
4. 상대경로에 넣어줍니다.
저는 상대경로에 넣는게 편해서 저기 두었는데,
편한 곳에 넣고 절대경로로 표기하셔도 괜찮아요!
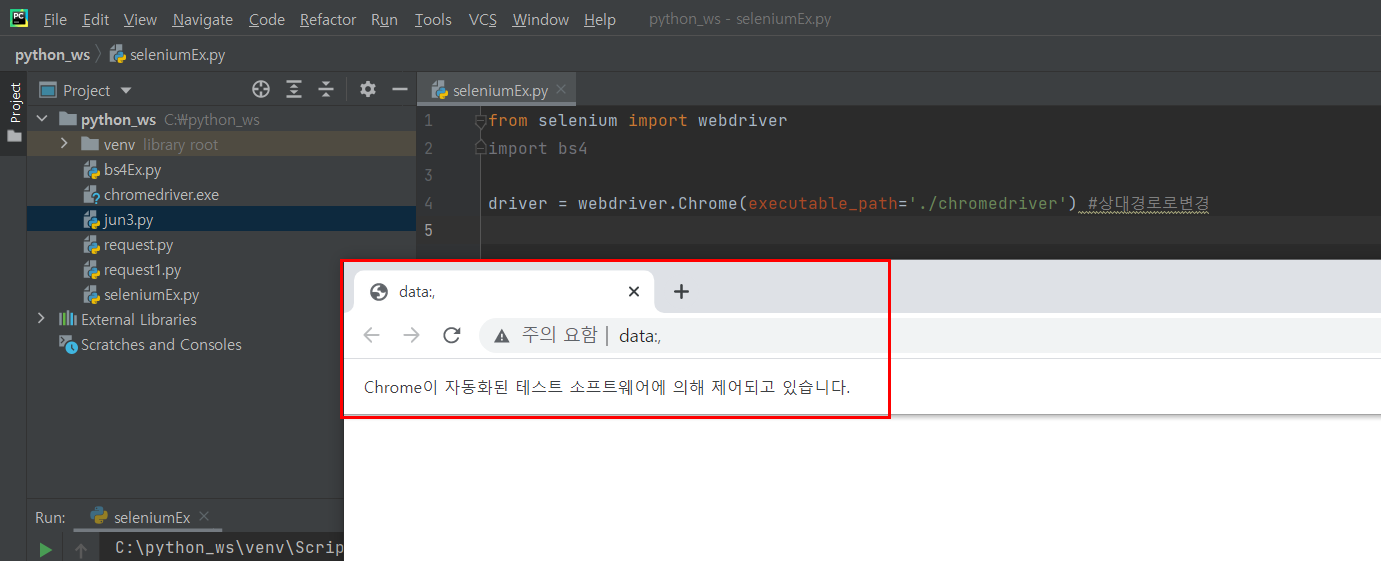
from selenium import webdriver
import bs4
driver = webdriver.Chrome(executable_path='./chromedriver') #상대경로로변경
빈창이 이렇게 뜹니다 :D
성공이에요!
from selenium import webdriver
import bs4
driver = webdriver.Chrome(executable_path='./chromedriver')
driver.get('https://www.naver.com')
soup = bs4.BeautifulSoup(driver.page_source, 'lxml') #
list = soup.find_all('div', class_='group_theme')
for a in list[0:]:
print(a.text.replace('\n',''))
print()
naver main에 div 태그 중에, group_theme 이라는 class명을 가지고 있는 내용을
가지고 오도록 해보았어요.

이렇게 줄줄 뜨네요!
replace를 한 이유는, 너무 줄바꿈이 많아서, 일부러 줄바꿈을 없앴습니다.
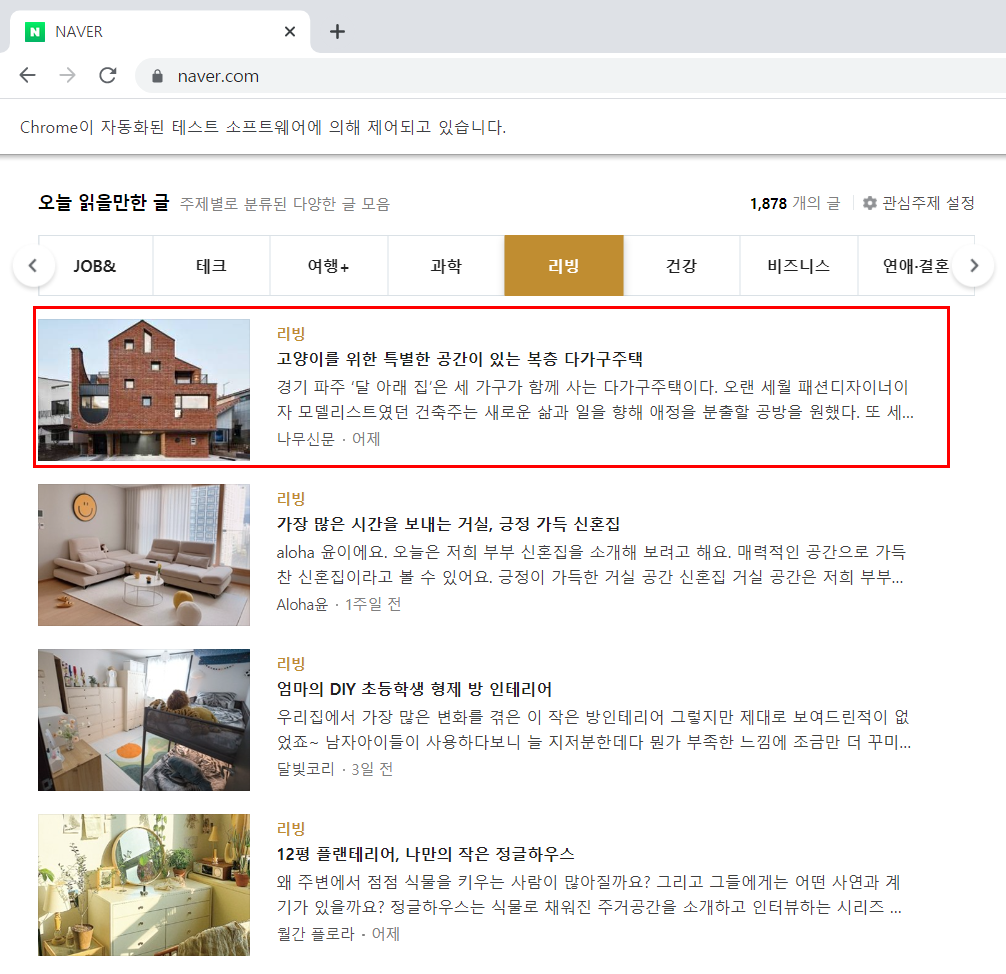
요렇게, 내용을 줄줄 읽어옵니다!
다른 예제로 또 돌아올게요!

'IT > crawling scraping' 카테고리의 다른 글
| 크롤링이란? Python Crawling 시작 - 유딩동 Tistory (0) | 2021.07.12 |
|---|---|
| [파이썬] 크롤링 BeautifulSoup 사용법, 웹크롤러 만들기 - 유딩동 Tistory (0) | 2021.06.08 |
| [파이썬] 크롤링 requests 패키지 임포트 - 유딩동 Tistory (0) | 2021.06.08 |


