[파이썬] 크롤링 BeautifulSoup 사용법, 웹크롤러 만들기 - 유딩동 Tistory
<body>
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-8261446056818366"
crossorigin="anonymous"></script>
<!-- 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-8261446056818366"
data-ad-slot="7914582292"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
안녕하세요, 유딩동입니다.
웹크롤러를 만들기 위해서 하나씩 차근차근
정리해보려고 합니다.
[파이썬] 크롤링 requests 패키지 임포트 - 유딩동 Tistory
안녕하세요, 유딩동입니다. 파이썬 크롤링에 앞서 패키지를 import 하는 글을 정리해 보았습니다. 사실 저는 거의 툴을 쓰지 않고 파이썬으로 프로젝트 개발을 거의 완료 한 상태인데 왜 이제서..
11uding.tistory.com
1. BeautifulSoup란?
뷰티플 수프는 HTML과 XML 문서를 파싱하기위한 파이썬 패키지입니다. 웹 스크래핑에 유용한 HTML에서 데이터를 추출하는 데 사용할 수있는 구문 분석 된 페이지에 대한 구문 분석 트리를 생성합니다
- 위키피디아
2. 사용법
: BeautifulSoup(파이썬객체로 바꿀 스트링, 파서)
- 파서란? 원시 코드인 순수 문자열 객체를 해석할 수있도록 분석하는 것.
i) lxml (가장 많이 사용!) : XML 해석이 가능한 파서, 파이썬 2.x/3.x 지원 가능, 빠른 속도(made by C)
ii) html5lib : 웹 브라우저 방식으로 HTML 해석, 느림, 파이썬 2.x 전용
iii) html.parser : 최신버전에선 사용 불가
-> 모두 pip을 이용하여 설치 가능
3. BeautifulSoup 예제
from bs4 import BeautifulSoup
html_doc = """<html>
<head>
<title>udingdong test</title>
</head>
<body>
<!-- Comment -->
<div class="title" id="div1">
<b>dingdong's blog</b>
</div>
블로그 글 리스트
<div class="list" id="div2">
여행기를 눌러주세요!
<a href="https://blog.naver.com/11uding/221739598294" class="blogList" id="link1">우흐티블린</a>
<a href="https://blog.naver.com/11uding/221727318231" class="blogList" id="link2">오로라항공후기</a>
</div>
<div class="detail" id="div3">
하단입니다1
</div>
<div class="detail" id="div3">
하단입니다2
</div>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'lxml')
print("=======div 태그 모두 찾기=======")
for div in soup.find_all("div"):
print(div)
print("\n=======div 태그 중 id가 div3인 것 2개 찾기=======")
for div in soup.find_all("div", id="div3", limit=2):
print(div)
print("\n=======div 태그 중 class명이 list인 것 찾기=======")
for div in soup.find_all("div", class_="list"):
print(div)
print("\n=======id, class명 찾기=======")
for div in soup.find_all("div", id="div2", class_="list"):
print(div)
=======div 태그 모두 찾기=======
for div in soup.find_all("div"):
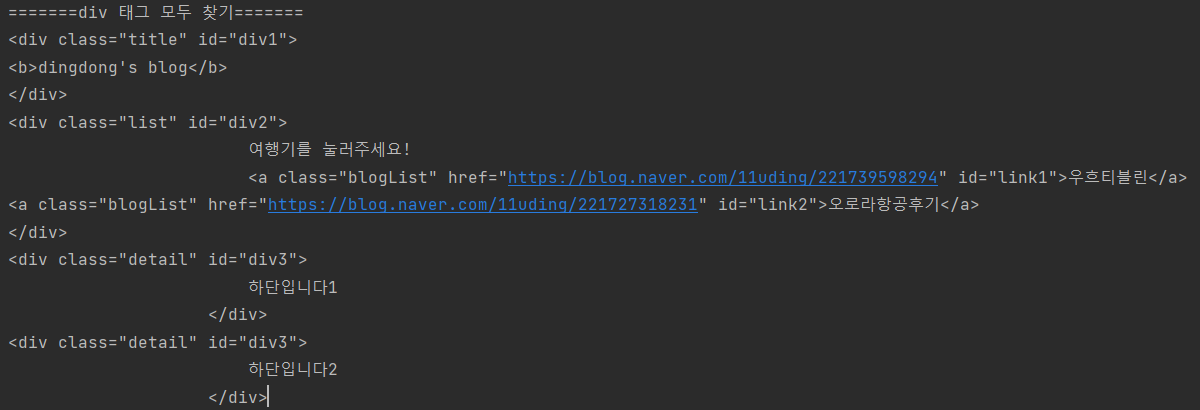
=======div 태그 중 id가 div3인 것 2개 찾기=======
for div in soup.find_all("div", id="div3", limit=2):
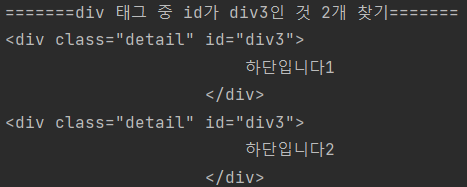
=======div 태그 중 class명이 list인 것 찾기=======
for div in soup.find_all("div", class_="list"):

=======id, class명 찾기=======
for div in soup.find_all("div", id="div2", class_="list"):

다음시간에는 셀레니움 정리를 해볼게요 :D